“…the direct to consumer aspect of the container model is at the heart of its transformative capabilities.”
Part 4 – The Tupperware Party
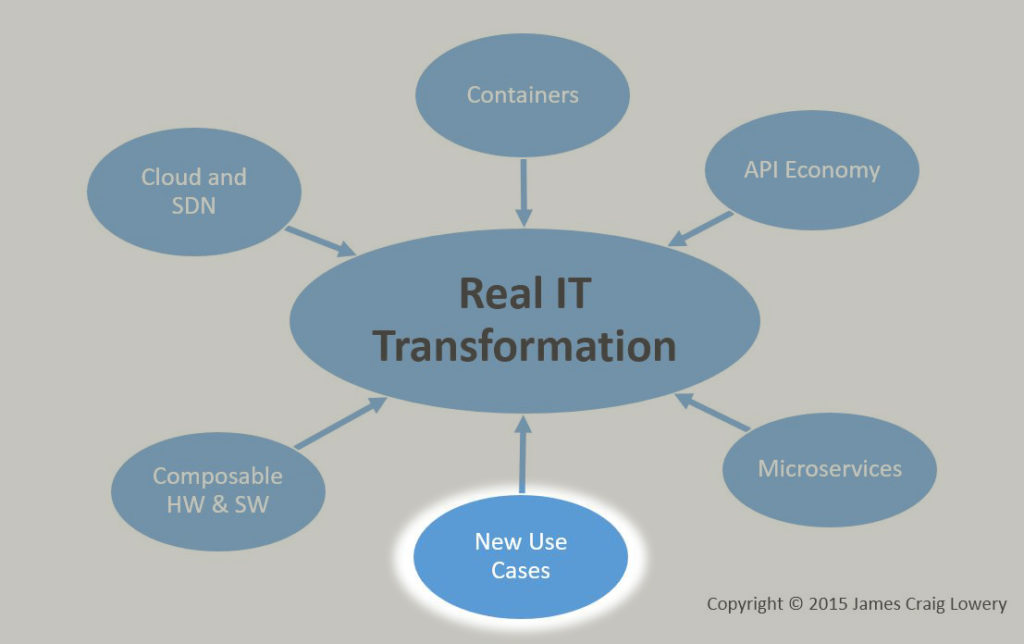
This is the fourth installment of a multi-part series relating six largely independent yet convergent evolutionary industry threads to one big IT revolution – a major Transformation. The first installment gives an overview of the diagram below, but today’s excursion is to consider the one at the top of the diagram because, at least for me, it’s the most recent to join the party, and the catalyst that seems to be causing acceleration of monumental change.

Why? The emergence of Docker as a technology darling has been atypical: Rarely does a startup see the kind of broad industry acknowledgement, if not outright support, it has garnered. For proof, look to the list of signatories for the Linux Foundation’s Open Container Initiative. I am hard pressed to find anyone who is anyone missing from that list: Amazon, Google, Microsoft, VMware, Cisco, HP, IBM, Dell, Oracle, Red Hat, Suse, … That’s just the short list. (Ok, Apple isn’t in there, but who would expect them to be?)
The point is, it isn’t all hype. In fact, the promise of Docker images and the flexibility of the runtime containers into which their payloads could be deployed is one of the first real glimpses we’ve seen of a universal Platform as a Service. (More on that when I talk about Microservices.) It takes us one step away from heavy x86-type virtualization of backing resources – such as CPU, disk, and memory – and closer to abstractions of things that software designers really care about, which are things like data structures, guaranteed persistence, and transactional flows.
At the risk of being overly pedagogical, I feel I should at least make a few points on “containers” and “Docker” about which many are often confused. Understanding these points is important to reading the tea leaves of the IT industry’s future.
First, “containers” is used interchangeably to refer to the image of an application in a package (like a Docker image), as well as the runtime environment into which that image can be placed. The latter is actually the more accurate definition, which is why you will see references in more technical literature to both Docker images and Docker containers. Images are the package. Containers are the target for their deployment.
To understand what’s in the package, let’s first understand what the containers, or runtime environments, are. The container concept itself is pretty broad: think of it like an apartment in an apartment complex where a program is going to spend its active life. Some apartments are grouped together into units, perhaps intentionally sharing things like drainage and water, or unintentionally sharing things like sounds. The degree of isolation, and how much of it is intentional or unintentional, is dependent upon the container technology.
Hypervisor-type virtualization such as VMware vSphere (ESX), Microsoft Hyper-V, and open source KVM create containers that look like x86 computer hardware. These containers are “heavyweight” because, to make use of them, one must install everything from the operating system “up.” Heavyweight virtualization basically “fakes out” an operating system and its attendant applications into thinking they have their own physical server. This approach has the merit of being very easy to understand and adopt by traditional IT shops because it fits their operational models of buying and managing servers. But, as a method of packaging, shipping, and deploying applications, it carries a lot of overhead.
The types of containers that are making today’s headlines are commonly called “lightweight,” which is common parlance for the more accurate label “operating system-level virtualization.” In this scenario, the operating system already exists, and the virtualization layer “fakes out” an application into thinking it has that operating system all to itself, instead of sharing it with others. By removing the need to ship entire operating system code in the package, and not imposing virtualization overhead on operating system intrinsics (kernel calls), a more efficient virtualization method is achieved. The size of the packages are potentially smaller as are the runtime resource footprints of the containers. It is generally faster to create, dispose, and modify them than an equivalent heavier-weight version.
The most well-known contemporary lightweight containers are based on Linux kernel cgroups functionality and file system unioning. Going into the details of how it works is beyond the scope of this ideally shorter post. More important, is that Linux containers are not the only lightweight containers in the world. In fact, they are not the only lightweight containers that Docker packaging will eventually support, and is in part why Microsoft announced a partnership with Docker earlier this year, and has signed on to the Linux Foundation OCI.
Perhaps the biggest misunderstanding at this juncture is that Microsoft’s Docker play is about running Windows applications on Linux in Docker containers. It isn’t, although that is a somewhat interesting tack. Instead, it is about being able to use Docker’s packaging (eventually, the OCI standard) to bundle up Windows applications into the same format as Linux applications, then use the same tools and repositories to manage and distribute those packages. Microsoft has its own equivalent of containers for Windows. It also recently announced Windows Nano Server, a JEOS (just-enough operating system) to create lightweight containers that Docker images of Windows payloads can target.
The figure below demonstrates what an ecosystem of mixed Linux and Windows containers could look like. Imagine having a repository of OCI-standard (i.e., Docker) images, the payloads of which are mixed – some being Linux apps (red hexagons), others being Windows apps (blue pentagons). The tools for managing the packages and the repo are based on the same standard, regardless of the payload. A person looking for an application can peruse an intermediate catalog of the repo and choose an application. Then they press “Purchase and Deploy,” the automation finds a cloud service that expresses a container API with the qualifier that it supports the type of payload (Windows or Linux), and the instance is deployed without the consumer of the application ever knowing the type of operating system it required.

Self-service catalogs and stores aren’t new, and that isn’t the point of the example. The point is that it becomes easier to develop and deliver software into such marketplaces without abandoning one’s preference of operating system as a developer or becoming deeply entrenched in one marketplace provider’s specific implementation, and it is easier for the application consumer to find and use applications in more places, paying less for the resources they use and without regard for details such as operating system. There is a more direct relationship between software providers and consumers, reducing or even eliminating the need for a middleman like traditional IT departments.
This is a powerful concept! It de-emphasizes the operating system on the consumption side, which forces a change in how IT departments must justify their existence. Instead of being dependency solvers – building and maintaining a physical plant, sourcing hardware, operating system, middleware, and staff to house and take care of it all – they must become brokers of the cloud services (public or private) that automatically provide those things. Ideally, they own the box labeled “Self-Service Catalog and Deployment Automation” in the figure, because that is the logic that both enables their customers to use cloud services easily, while the organization maintains control over what is deployed and to where.
This is a radical departure from the status-quo. When I raised the concept in a recent discussion, it was met with disbelief, and even some ridicule. Specifically, the comment was that the demise of IT has been predicted by many people on many previous occasions, and it has yet to happen. Although I do not predict its demise, I do foresee one of the biggest changes to that set of disciplines since the x86 server went mainstream.
If there’s anything I’ve learned in this industry, it is that the unexpected can and will happen. The unthinkable was 100% certain to occur when viewed in hindsight, which is too late. Tupperware (the company) is best known for defining an entire category of home storage products, notably the famous “burping” container. But more profound and what enabled it to best its competitors was the development of its direct marketing methods: the similarly iconic Tupperware Party. For cloud computing, the container as technology is certainly interesting, but it’s the bypassing of the middleman – the direct to consumer aspect of the model – that is really at the heart of its transformative capabilities.
Welcome to the party.